再次见到你,真好。
4月1日愚人节,也是张国荣的忌日。今天,在哥哥张国荣离开的第16个年头,有网友用AI让张国荣“复活”,并且演唱了经典歌曲《千千阙歌》、《玻璃之情》。
在视频中,AI“复活”的哥哥正在录音棚中录着歌曲,开场一开口,从唱歌的表情、动作都与张国荣颇为神似。网友们不经大呼:“太像了”、“泪目”、“哭了”、“想你了,哥哥”。

张国荣是那般的传奇,芳华绝代,尽管去世16年,但每年的4月1日,人们一直想努力把他的每一面都留下来,今年是AI。
AI“复活”张国荣6分钟
这段视频长达6分钟,“张国荣”分别穿着两套衣服唱完两首歌,而这些镜头,也让网友们不禁感慨:他仿佛从未离开过。

而在录制第二首歌曲时,出现了一个特别有意思的镜头:哥哥竟然在直播!

新智元了解到,“复活”张国荣视频的作者是来自B站的Up主QuantumLiu(知乎“天清”),目前在国内视觉特效公司Studio51做技术。
据该Up主描述,张国荣的视频使用了自主研发的AI换脸技术,清晰度、还原度均领先于业内其他使用Deepfakes的效果,张国荣视频的分辨率也达到了1080P。
QuantumLiu告诉新智元,换脸视频中的男生跟张国荣长相差距很大,“是个北方汉子”,但是歌曲是“北方汉子”原声,没有用张国荣的原声,也没经过处理。
这个6分钟左右的视频,从拍摄和录音、剪辑,前后花了一个多星期左右时间,积累的原素材大概是20分钟,做换脸真正的运算时间只有8个小时左右。
“我们用的是变分自动编码器,借鉴了deepfakes的思路,但是解决了很多问题,比如高质量数据,鲁棒性,训练速度,分布式训练,还结合公司特效业务的经验,优化了合成环节,让放回视频里的人脸融合得更自然。相比于其他使用开源程序的爱好者,我们是一个即将商用的系统,高达1080p+的分辨率是其他人做不到的。”
QuantumLiu说,下一步,公司会利用高清的优势和在影视行业的业务,进军影视级别高清换脸,并开发换脸开放平台,让所有人都可以玩转视频换脸。
朱茵变杨幂,分辨率低好操作
其实,AI换脸并不是非常新鲜的技术了。前一阵子便有朱茵变杨幂,海王变徐锦江的相关报道。

《射雕英雄传》中,朱茵变杨幂

海王变徐锦江
这些技术的背后,是2017年年底的Deepfakes软件带来的结果。当时Reddit用户Deepfakes,将《神奇女侠》的女主角盖尔·加朵、以及艾玛沃森、斯嘉丽等众多女明星的脸跟AV女优进行了交换,制作出足以以假乱真的爱情动作片。

不过,QuantumLiu认为,目前的网上的作品都是用一个基础fakeapp软件去做的,纯娱乐,所以只能找那些很低分辨率的片段去更换(比如朱茵变杨幂)。
国内也有过银幕上的换脸。在2017年科幻喜剧《不可思异》中,当时由于演员的原因,片方不得不临时换角,由大鹏代替杜汶泽所有戏份,进行了一次“特效换脸”手术。

但这次换脸,是用通过纯手工的方式一帧帧地修改画面,耗时将近6个月,才将影片中所有的镜头都换完。在价格上,可以说是“一秒千金”。

而AI换脸和后期换脸有着根本区别。后者还需要各种建模,以及一桢一桢的修改,前者在操作上只需要提供足够多的素材让机器学习。
另外,目前以fakeApp为代表的应用存在分辨率低、效果不稳定、渲染时间长的问题。QuantumLiu介绍,用AI和特效技术解决连续针断点再融入难题,one shot面部自适应,机器自主学习光感和画面匹配度,每一次的训练都会自动叠带,成功率,效果和渲染速度大幅提高,动态视频的切换更加完美的匹配。目前已经取得了高分辨率光感匹配的突破和叠加式渲染的突破。已经可以在几个小时内完成一整部片的替换,而且计算机学习的速度越来越快,时间周期还在不断的缩短,品质不断提高。
Deepfakes技术详解
QuantumLiu将在近期发布张国荣“复活”视频的具体实现方法,在他发布之前,我们先来了解下Deepfakes的技术内容。
Deepfakes 使用生成对抗网络(GAN),其中两个机器学习模型进行了较量。一个ML模型在数据集上进行训练,然后创建伪造的视频,而另一个模型尝试检测伪造。伪造者创建假视频,直到另一个ML模型无法检测到伪造。训练数据集越大,伪造者越容易创建可信的deepfake视频。

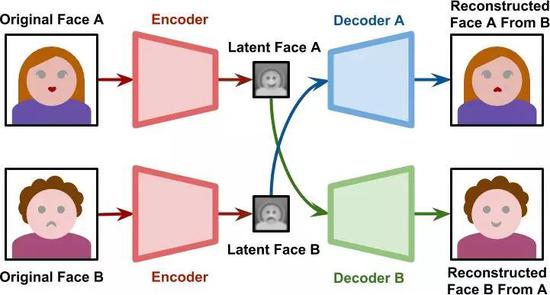
上图显示了一个图像(在本例中是一张脸)被输入到编码器(encoder)中。其结果是同一张脸的低维表示,有时被称为latent face。根据网络架构的不同,latent face可能根本不像人脸。当通过解码器(decoder)时,latent face被重建。自动编码器是有损的,因此重建的脸不太可能有原来的细节水平。
程序员可以完全控制网络的形状:有多少层,每层有多少节点,以及它们如何连接。网络的真实知识存储在连接节点的边缘。每条边都有一个权重,找到使自动编码器能够像描述的那样工作的正确权重集是一个耗时的过程。
训练神经网络意味着优化其权重以达到特定的目标。在传统的自动编码器的情况下,网络的性能取决于它如何根据其潜在空间的表示重建原始图像。
训练Deepfakes
需要注意的是,如果我们单独训练两个自动编码器,它们将互不兼容。latent faces基于每个网络在其训练过程中认为有意义的特定特征。但是如果将两个自动编码器分别在不同的人脸上训练,它们的潜在空间将代表不同的特征。
使人脸交换技术成为可能的是找到一种方法来强制将两个潜在的人脸在相同的特征上编码。Deepfakes通过让两个网络共享相同的编码器,然后使用两个不同的解码器来解决这个问题。

在训练阶段,这两个网络需要分开处理。解码器A仅用A的人脸来训练;解码器B只用B的人脸来训练,但是所有的latent face都是由同一个编码器产生的。这意味着编码器本身必须识别两个人脸中的共同特征。因为所有的人脸都具有相似的结构,所以编码器学习“人脸”本身的概念是合理的。
生成Deepfakes
当训练过程完成后,我们可以将A生成的一个latent face传递给解码器B。如下图所示,解码器B将尝试从与A相关的信息中重构B。
如果网络已经很好地概括了人脸的构成,那么潜在空间将表示面部表情和方向。这意味着可以为B生成与A的表情和方向相同的人脸。
请看下面的动图。左边,UI艺术家Anisa Sanusi的脸被从一个视频中提取并对齐。右边,一个训练好的神经网络正在重建游戏设计师Henry Hoffman的脸,以匹配Anisa的表情。

显然,Deepfakes背后的技术并不受人脸的限制。例如,它可以用来把苹果变成猕猴桃。

重要的是,训练中使用的两个主体要有尽可能多的相似之处。这是为了确保共享编码器能够泛化易于传输的有意义的特性。虽然这项技术对人脸和水果都有效,但不太可能将人脸变成水果。
若是你的记忆中也有哥哥的身影,那就分享这篇文章,让更多的人看到哥哥的视频吧!





















